意藍 AI Search 是什麼?
工作流程、平台優勢及落地應用實例

AI Search 工作流程
為更具體說明 AI Search 的運作機制,以下將從資料處理到智慧問答生成,逐步解析 AI Search 的核心工作流程:
首先,以 AI彙整各種知識文件、數據庫或市場情報等資料,透過強大的數據處理、語意分析與搜尋技術處理後,再經由 eLAND AI Search API 、 eLAND Active RAGᵀᴹ(獨家主動式檢索增強生成架構)及意藍自主研發的大語言模型 eLAND GOAT 進行語意分析與理解,進而實現高品質的智慧問答與內容生成。最終,AI Search 可部署於企業安全可信賴的雲端或地端環境,有效支援知識管理、工作區協作及代理任務等多元化應用場景。
AI Search 的產品化落地:AI Search for KM 平台介紹
AI Search 是一套具備高度延伸性的核心技術流程,目前意藍已以此為基礎,發展出涵蓋知識管理、電商應用等多項應用服務。本篇以「新一代 GenAI 知識管理工作平台 AI Search for KM」 為例,說明 AI Search 如何在實際的組織應用場域中落地,協助進行知識管理。
在實務上,AI Search for KM 具備四大功能優勢:
- 支援多種資料來源與格式
可支援各種企業常見檔案格式,包含網頁、壓縮檔、PDF 和郵件檔等。 - 問答設定可根據不同情境,選擇模型與回應模式
用戶能根據不同使用情境,選擇適合的大語言模型(如eLAND GOAT、GPT系列、Gemini及Claude等)與回覆模式。 - 搜尋內外部資料源,並可靈活優化查詢結果
可彈性選擇參考資料的來源,包括參考內部的特定文件或外部特定來源的輿情,並採用混合式搜尋,能夠動態調整全文檢索與向量搜尋的排序比重,確保最終結果貼近用戶的詢問意圖。 - 可自訂提示詞,生成符合特定架構的報告
用戶可透過設定提示詞,指定大語言模型生成特定語調、格式或範本之報告,系統亦會詳列參考資料來源,確保內容具備高可信度。
AI Search for KM 於政府之應用:循政決策與智慧治理
在眾多應用場域中,政府公部門的智慧治理因涉及政策研析、跨來源資料整合與高度合規要求,是生成式 AI 技術落地門檻最高的場域之一。而 AI Search for KM 憑藉成熟的架構與低導入難度,不僅能快速導入政府部門,更能滿足政府機關的日常業務需求,成為推動智慧治理的關鍵助力。其應用範疇廣泛,涵蓋:
- 新聞稿撰寫:政策宣達與闢謠
- 循證治理:輔助政策評估制定
- 合規確認:確保業務合乎法規
- 公文/陳情回應:提高民意溝通速度
- 施政擬答:高效彙整施政成果
- 報告產製:提升議題分析效率
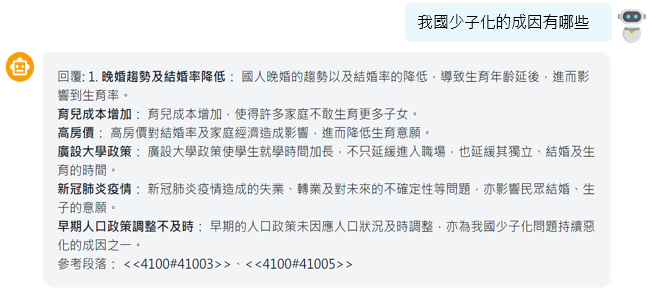
以「循證治理」的實務應用為例,系統曾協助公部門深入研究「少子女化及晚婚不婚」等複雜社會課題。透過分析社群輿情數據、利害關係人的相關討論內容、施政成果、論文期刊及結構化統計數據等資料,回答用戶的問題。
系統可在以下循證決策的三大階段提供輔助:
- 拆解課題的構成要素,設定研究切角:如針對少子化成因,系統能自動條列式分析社會、經濟等多重影響因素
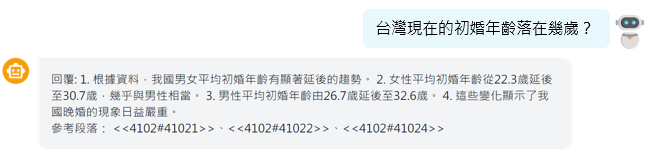
- 調閱研究課題的實際數據:針對台灣初婚年齡等具體指標,系統可即時引用精確數據進行回答
- 回顧政策成果,評估施政成效:統整過往政府推動之婚育政策及其執行數據,協助評估政策成效

綜上所述,意藍透過 AI Search 的核心技術流程,能成功將龐雜的內外部數據整合並轉化為具備「可解釋性」與「精準度」的決策資源。導入 AI Search 不僅能優化組織內的知識管理效率,更能跨足公部門實踐智慧治理,透過系統化的循證決策機制,輔助政策制定者針對複雜的社會課題,做出以數據驅動的精確決策。
常見問題 FAQ
Q1:為何企業組織需要導入 AI Search?
A: AI Search 能將碎片化的資訊轉化為結構化的答案,使用者不需設定精準的關鍵字,透過自然語言提問即可獲得相關且可追溯的答案,能大幅提升工作中資訊檢索的效率。
AI Search 能協助全面優化企業工作,包括在新人自助學習、員工資訊查找、重複性報告生成及客戶智能問答等應用情境,皆能有效提升資訊蒐集及內容產出的品質與效率。
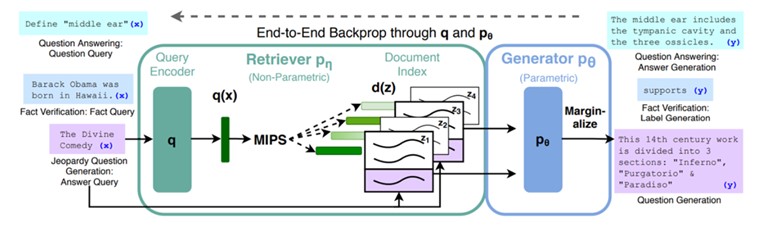
Q2:eLAND Active RAGᵀᴹ (主動式檢索)跟一般 RAG 有什麼差別?
A:最大的差別在於「主動性」與「多回合推理」。
傳統 RAG 通常只進行一次性檢索,可以回答簡單問題,但遇到複雜問題時容易資訊不足。eLAND Active RAGᵀᴹ(主動式檢索增強生成)是在RAG(檢索增強生成)的基礎上進一步升級的技術,能夠主動拆解任務,根據初步結果動態調整查詢策略,並進行多回合查詢。eLAND Active RAGᵀᴹ 就像是一個會思考的助理,在回覆前會反覆確認資料是否充足,確保答案更深、更準。
Q3:什麼是eLAND GOAT?
A:eLAND GOAT 是意藍自行研發的大語言模型,其特色在於能提供更強的檢索增強生成能力(Retrieval-Augmented Generation,RAG)。
eLAND GOAT 具備更好的繁體中文理解、生成能力,在使用上能夠提供更為在地化的體驗,且能夠部署於地端,運行在企業內部環境中,依循企業組織的權限設定,滿足企業對於資安上的需求。
Q4:知識管理系統為什麼能輔助智慧治理?
A:知識管理系統可以系統性的蒐集及整合組織所需的知識資源,讓資料易於被查找及利用,有助於決策者進行循證決策,意即以統計數據等客觀資料為政策制定的依據,而非依靠主觀判斷或過往經驗。
以AI Search for KM 為例,在協助處理如少子女化等複雜課題時,AI Search for KM 能瞬間調閱大量研究報告、社群輿情及施政數據,協助決策者從拆解成因、調閱數據到評估成效進行一站式分析。不僅縮短了資料彙整的時間,更確保每一項政策制定都有具體的統計事實與民意數據作為基礎,實現智慧治理的目標。
Q5:什麼是「混合式搜尋」?為什麼它有助於提升搜尋準確度?
A:混合式搜尋(Hybrid Search)結合了「全文檢索」與「向量搜尋」的優點,既能精準匹配關鍵字,亦能深度理解問題語意。
傳統搜尋依賴關鍵字精準匹配,若打錯字就找不到準確資料;而向量搜尋則依賴語意關聯,能找到最相關的資料。AI Search for KM 提供的混合式搜尋可動態調整兩者的權重,例如在尋找特定「法規編號」時側重全文檢索,在詢問「如何提升生育率」時則側重語意分析。此種靈活的調整機制,讓 AI 在面對專業術語與自然語言提問時,都能給出最貼近用戶意圖的答案。
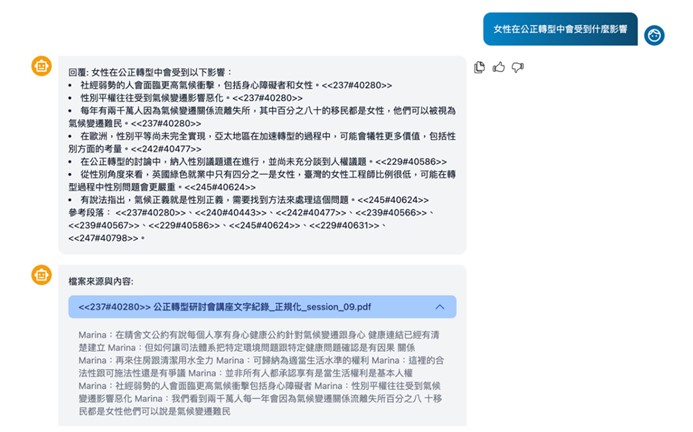
Q6:AI Search for KM 如何確保產出的答案具備「可追溯性」?
A:透過「來源標註」機制,系統會確保每個答案的來源都可被驗證。
AI Search for KM在生成回答時,並非憑空產出文字,而是從知識庫中提取資訊。系統在回答的段落末尾標示參考來源,使用者可閱覽原始檔案進行二次查證。這種「言有所本」的機制,能有效降低幻覺風險,建立人機協作的信任感。















")
")
")