金融情資調查如何自動化?
AI 輔助選案與情資分析效率與品質
為提升選案效率與準確度,意藍協助政府調查單位建構「金融情報整合 AI 分析系統」,強化情資分析與選案能力,使偵查流程更具系統性與一致性。
本期 AI 知識庫亮點

調查單位背景與需求介紹
因此,如何將相關情資進行有效整合,提升分析的一致性與可追溯性,並在案件成形前,及早辨識潛在高風險交易,成為調查單位希望解決的核心需求。
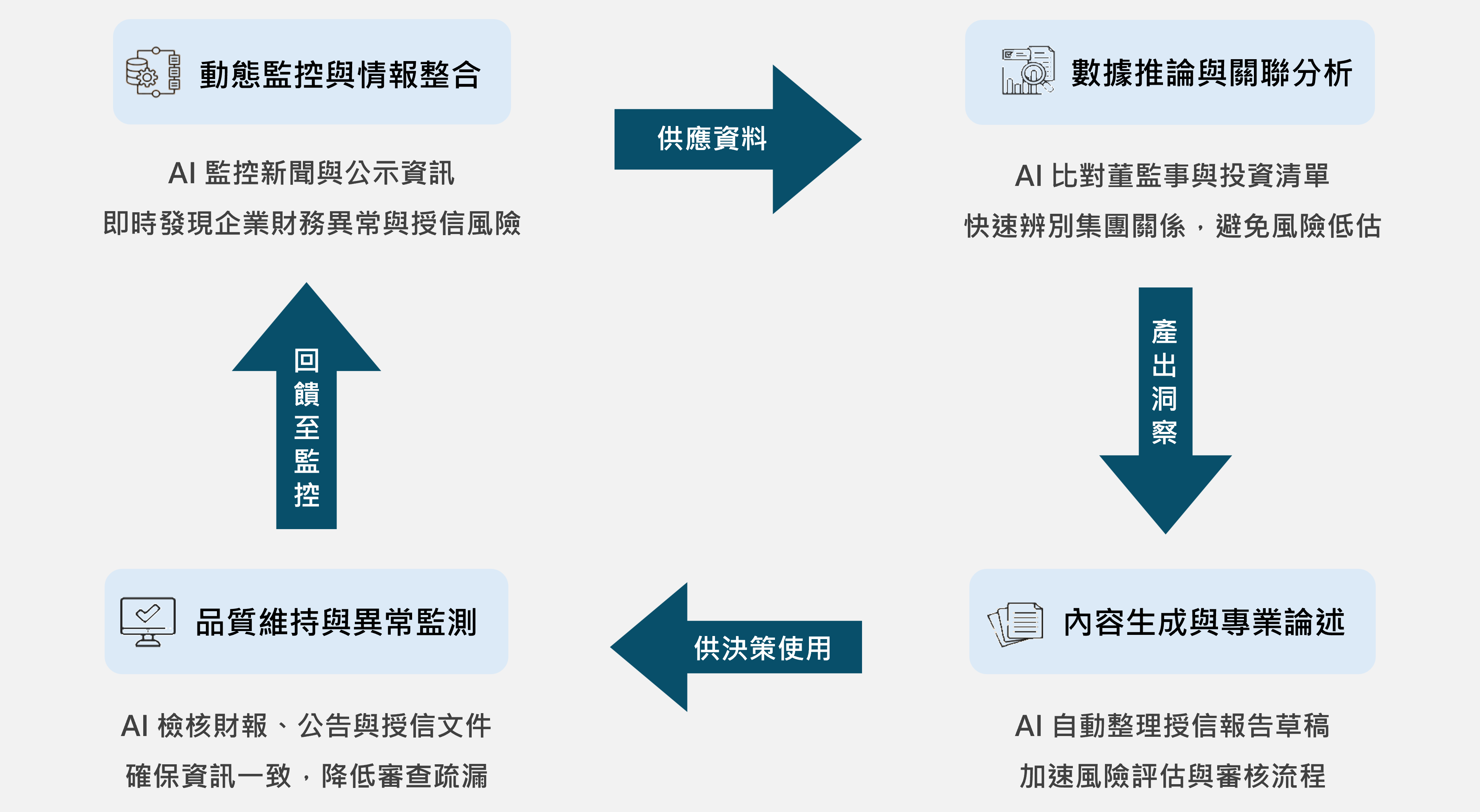
導入「金融情報整合 AI 分析系統」助力選案及偵查
- 資料整合與重建:整合大額現金交易報告(CTR)、可疑交易報告(STR)及國際情資三大來源,為調查單位重建金融情資資料庫,並重新規劃資料欄位與內容格式,使不同來源的資料能以統一標準被檢索與比對,打造高效的金融情資分析基礎。
- 自動分析與智慧選案:系統將交易資料依照匯款頻率、金額、來源去向等行為特徵進行比對,再依據常見犯罪手法(如分散交易、層層轉手、短時間高頻率往返等)進行交易模式分析,協助辨識具有較高風險的交易群組與潛藏的特定犯罪行為;此外,系統也能依照不同情境調整篩選與分析條件,具備良好實務應用效率。
- 直覺式查詢:提供簡便完整的操作介面,當單位人員輸入多種查詢條件 ,系統便會自動整合既有資料並呈現關聯結果,讓案件背景、交易脈絡與可疑指標一目瞭然,減少在多套系統間反覆切換的作業時間。
- 權限控管與資安合規:依據不同使用者的角色控管權限,完整保留操作與查詢紀錄,以符合資安與稽核要求。
- 優化情資處理流程:藉由將多源金融情資整合至同一平台並建立標準化機制,減少人工蒐整與比對成本,使研析情資流程更加流暢。
- 提高情報掌握度:藉由系統提供的自動標註、紀錄與追蹤能力,有助於及早從大量資料中辨識出可疑交易群組,調查單位也能完整掌握可疑資金流向與案件背景。
- 強化選案精確度:透過模型輔助分析交易行為特徵,讓研析過程判斷維持一致邏輯,減少因人員經驗產生的影響,提升案件辨識的精確性。
- 降低學習成本:標準化的操作介面與使用方式,幫助新進同仁快速接軌,不再需要仰賴資深同仁的教學指導,讓知識能在單位內快速傳承,進而提升工作品質及效率。
透過使用此系統,調查單位能更即時地掌握金融情資流向,快速鎖定異常交易,大幅縮短人工篩選時間,提升辦案效率與精準度,實現資料登錄、查詢、選案與派案的全流程優化。
常見問題 FAQ
Q1:為什麼金融情資調查需要導入 AI 自動化系統?
A:主因是金融交易量龐大且犯罪手法複雜,傳統人工比對已無法應對即時偵測需求。
調查單位每天需處理海量的大額交易(CTR)與可疑交易(STR)報告,資料來源多樣且格式不一。若僅靠人工篩選,容易因人員經驗差異導致判斷標準不一,甚至遺漏潛在風險。AI 能提供統一的邏輯與海量處理能力,確保研析過程的一致性與精確度。
Q2:AI 如何從大量交易中辨識出潛在的洗錢或詐騙案件?
A:AI 透過分析「行為特徵」與「交易模式」來識別高風險群組。
系統會根據匯款頻率、金額大小、資金去向等特徵,比對常見的犯罪手法,例如「分散交易」、「層層轉手」或「短時間高頻往返」等。透過 AI 的模式識別能力,能主動標註出具有異常行為的交易群組,讓調查官能及早鎖定高風險案件。
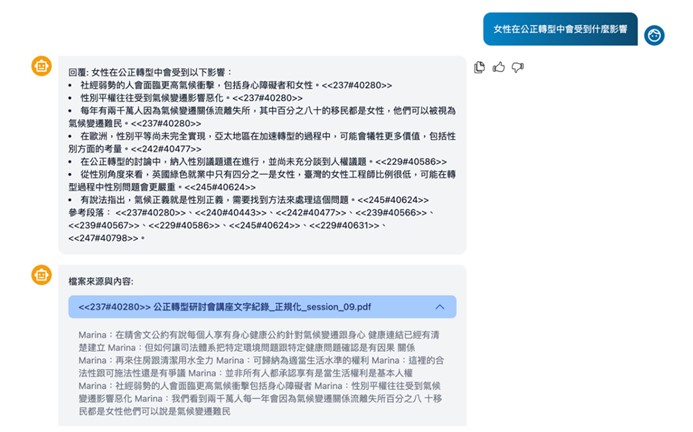
Q3:什麼是「RAG 架構」?它如何提升金融情資的分析品質?
A:RAG(檢索增強生成)架構能確保 AI 生成的研析結果具備可追溯性與真實依據。
在金融情報整合系統中,RAG 技術會先從資料庫檢索相關的原始交易紀錄,再交由 AI 進行語意分析與統整。這不僅能確保回覆內容精準,更能標註資料來源(如特定的 STR 編號),滿足執法單位對於證據鏈與稽核的高標準要求。
Q4:AI 如何整合來源不同的 CTR、STR 與國際情資?
A:系統透過「資料重建」技術,將多源資料轉化為標準化的統一格式。
意藍的系統會重新規劃不同來源的資料欄位,打破資訊孤島,使原本散落在各處的情資能以統一標準被檢索與交叉比對。這讓調查人員能在單一平台掌握完整的案件背景,不需在多個系統間反覆切換。
Q5:AI 系統如何降低新進調查人員的學習成本與判斷誤差?
A:透過「直覺式查詢介面」與「標準化研析邏輯」,減少對個人經驗的過度依賴。
系統提供簡便的操作介面,新進同仁不需掌握複雜的查詢語言,只要輸入關鍵字即可呈現關聯結果。此外,AI 輔助選案能維持一致的判斷邏輯,讓知識能在單位內快速傳承,不再需要長期仰賴資深同仁的口耳相傳。
Q6:處理敏感的金融交易情資,系統在資安與權限控管上有何保障?
A:意藍「金融情報整合 AI 分析系統」具備嚴格的角色權限控管與完整的查詢紀錄留存。
考慮到金融情資的高度機敏性,系統會依據使用者的職權劃分存取範圍,並完整保留每一筆操作與查詢軌跡。這不僅符合資安合規與內部稽核要求,更能確保偵查過程中的資料完整性與不被濫用。
Q7:導入「金融情報整合 AI 分析系統」後,對辦案流程有何具體提升?
A:系統能實現「資料登錄、查詢、選案到派案」的全流程優化。
透過自動標註與智慧選案,調查單位能及早辨識出高風險交易,大幅縮短人工初步篩選的時間。這讓調查官能將精力集中在深度案件研析與實體調查,全面提升辦案效率與情報掌握度,達到精準打擊犯罪的目標。