生成式AI的簡介與應用

生成式AI與人工智慧技術簡介
- 監督式學習:我們告訴模型一些範例資料和答案,模型學到資料和答案之間具有鑑別力的特徵後,就可以依樣畫葫蘆去進行分類或預測。
- 非監督式學習:給模型一批資料但不告訴它答案,讓模型自己找到資料當中重要的特徵進行分群。
- 增強式學習:不給模型訓練資料,但告訴它目標及獎勵機制是什麼(怎麼做會得分、怎麼做會扣分),讓模型自行嘗試找出達到高分的方法。
生成式AI背後的技術原理:大語言模型
生成式AI所依靠的其中一個技術便是「大型語言模型」(Large Language Model, LLM),其特色在於訓練過程中,模型可以自大量資料中自行學習和理解每個詞、每個句子之間的關係與背後的意義,最後根據指令,提供符合邏輯的自然語言回應。好比文字接龍,參與者需要根據已知的詞語來生成符合規則的新詞語,大型語言模型在接收問題後,會基於訓練數據和上下文,來評估問題背後最高機率會出現的字詞是什麼,然後一字一字生成出來,最終形成完整且符合邏輯的回答。
而相較於傳統的自然語言處理技術,大型語言模型的優勢有三:- 上下文理解:大型語言模型能更好地理解和處理文意,生成的回應更連貫且有邏輯。
- 多任務適用:大型語言模型能夠應付多種自然語言處理的任務,不需要單獨為每種任務來設計特定模型,也因此應用更多更廣。
- 大規模資料:大型語言模型用以訓練的文本資料通常十分龐大,可能是幾千萬甚至幾億的語料,讓模型能夠掌握豐富的知識,做出更準確的理解與回覆。
生成式AI的痛點、挑戰與解方
不過,從2023年劍橋字典選出的年度代表字:Hallucination,幻想,其實就反應了AI的可信賴性是一大挑戰,因為生成式AI對於沒看過的資訊會想辦法拼湊出答案。模型生成的內容可能表面上看起來合理,實際上卻缺乏真實的參考來源,這種現象在回答專業知識問題時更為明顯,因為模型可能傾向根據在訓練數據中學到的資料來生成答案,而非真正理解問題及實際參考文章來進行答覆。
面對上述問題,檢索增強生成(Retrieval-Augmented Generation, RAG)技術是一個良好的解決方案。RAG是2020年由Patrick Lewis提出,其結合了檢索和生成式AI的優勢,首先檢索外部資料庫中的相關資訊,再基於這些資訊生成回答,藉此減少憑空杜撰的可能性、增強回覆的相關性和真實性,進一步提升問答效果,確保符合實際應用需求。
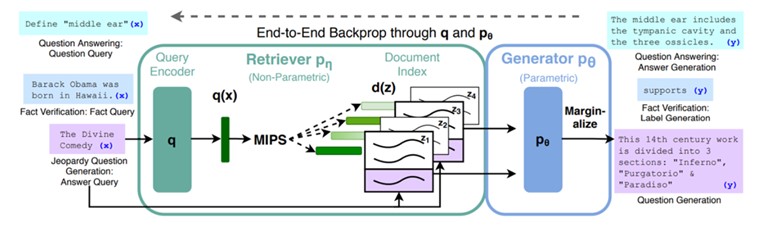
▲檢索增強生成技術(Lewis, P., 2020)
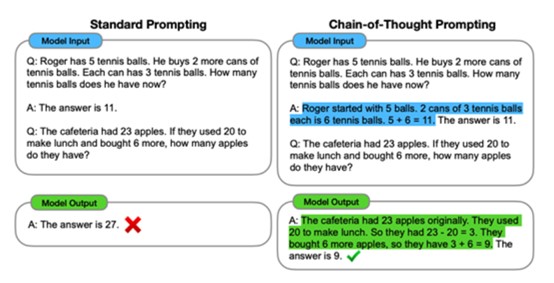
▲思維鏈(Wei, J., 2022)
生成式AI的應用實例
- 透過大型語言模型對文本進行摘要,找出重點
在進行政策評估時,會需要針對如會議記錄、訪談內容、問卷中的開放式問題或網路輿情等資料進行質性分析,以歸納出多元利害關係人的相關意見或質疑。此時,結合自然語言處理(Natural Language Processing, NLP)技術與大型語言模型(Large Language Model, LLM),便能夠讓分析更有效率,避免過去逐篇檢視文本後才能找出重點的耗時過程。
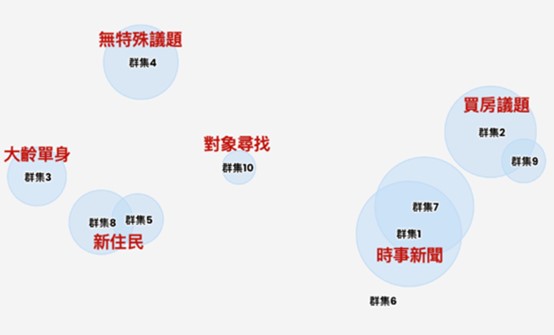
首先,為瞭解民眾對於議題有哪些重要的意見面向,可藉由AI語意模型對民眾言論文本進行「重要關鍵字提取」與「語意相似度計算」,並輔以分群演算法將相似討論進行歸類,拆解出不同的討論面向,作為政策評估時的參考。下圖是「晚婚 / 不婚議題」在社群討論當中的分群結果,圓圈大小代表討論的顯著(集中)程度,而圓圈彼此之間的距離則代表討論的相似程度。

- RAG:搜尋引擎結合大型語言模型,提升研究效率
針對政策評估時所蒐集的大量質性資料,過去往往需要花費大量時間解讀,才能從中找出關鍵課題。透過檢索增強生成(Retrieval-Augmented Generation, RAG)技術,將搜尋引擎與生成式AI優勢相融合,便能快速將文本資料中的重點知識內容,轉化成淺顯易懂的重點說明。
首先,搜尋引擎能夠直接對多種格式的文件進行文本上的解析,在搜尋時也能夠進行跨檔案的比對;生成式AI演算法則可以探索和分析複雜的資料。在針對某個議題、概念進行研究時,「搜尋引擎 + 生成式AI」能夠即時從龐大的資料庫中搜尋相關命中段落,並將這些內容快速摘要呈現;透過理解語言的結構和語境,也能確保命中段落的展示是精確且相關的。
簡言之,RAG是在檢索讀取(Retrieve-Read)的框架下進行搜尋(Yunfan, G. ,et al, 2023),能夠識別並找尋給定的相關資訊需求(Zhao, P. , et al, 2024),基於對命中段落的理解,使生成式AI能夠進一步生成摘要,協助使用者在短時間內獲得專業且易理解的回覆,避免在研究、搜集過程中浪費時間在無關或不確切的資訊上。例如,面對大量的訪談逐字稿文件,透過RAG技術進行知識搜尋與知識問答,分析者不僅能彙整並凸顯資料中的重要發現,還能驗證對特定解釋的認知是否正確。此外,它也提供了深入洞察,如識別特定發言者在資料中的關鍵觀點,或對比不同發言者對同議題的立場。
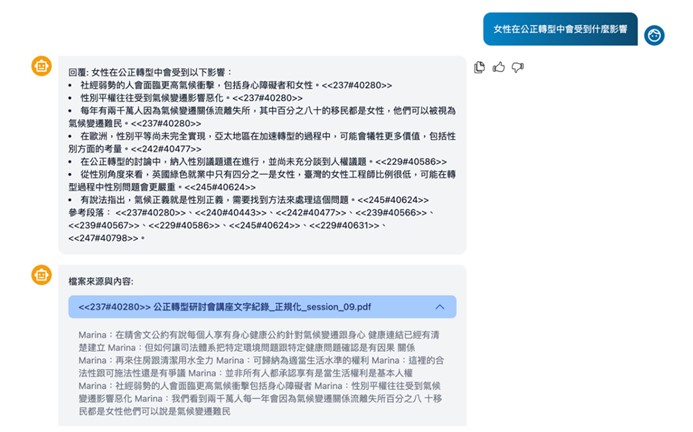
下圖呈現RAG技術如何在資料中發現重點,針對公正轉型研討會講座文字記錄文件進行提問,試問「女性在公正轉型中會受到什麼影響」,RAG迅速對該文件進行搜索,並以條列式回覆重點摘要,同時將參考段落的位置標示出來。





")
")
")