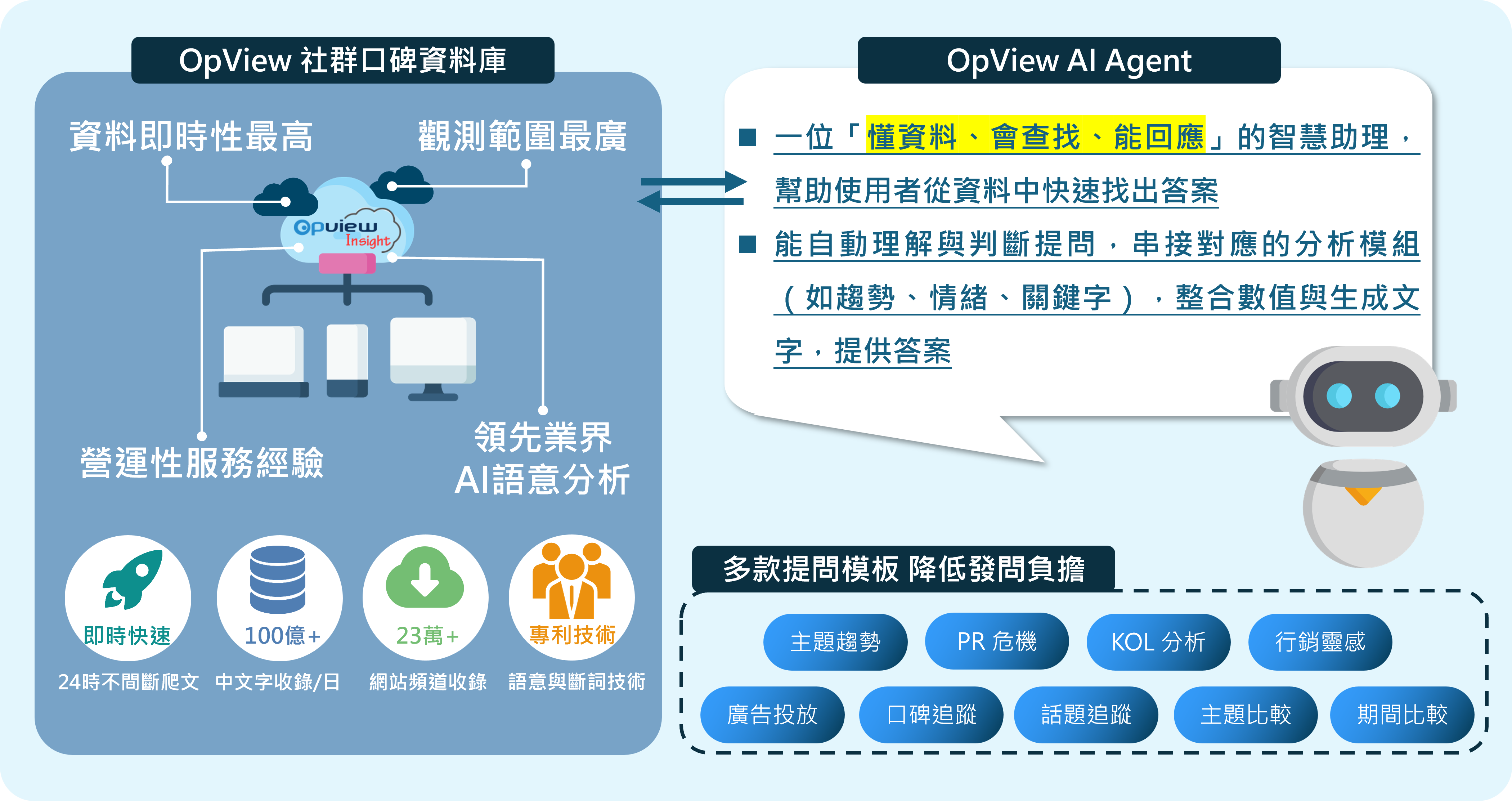
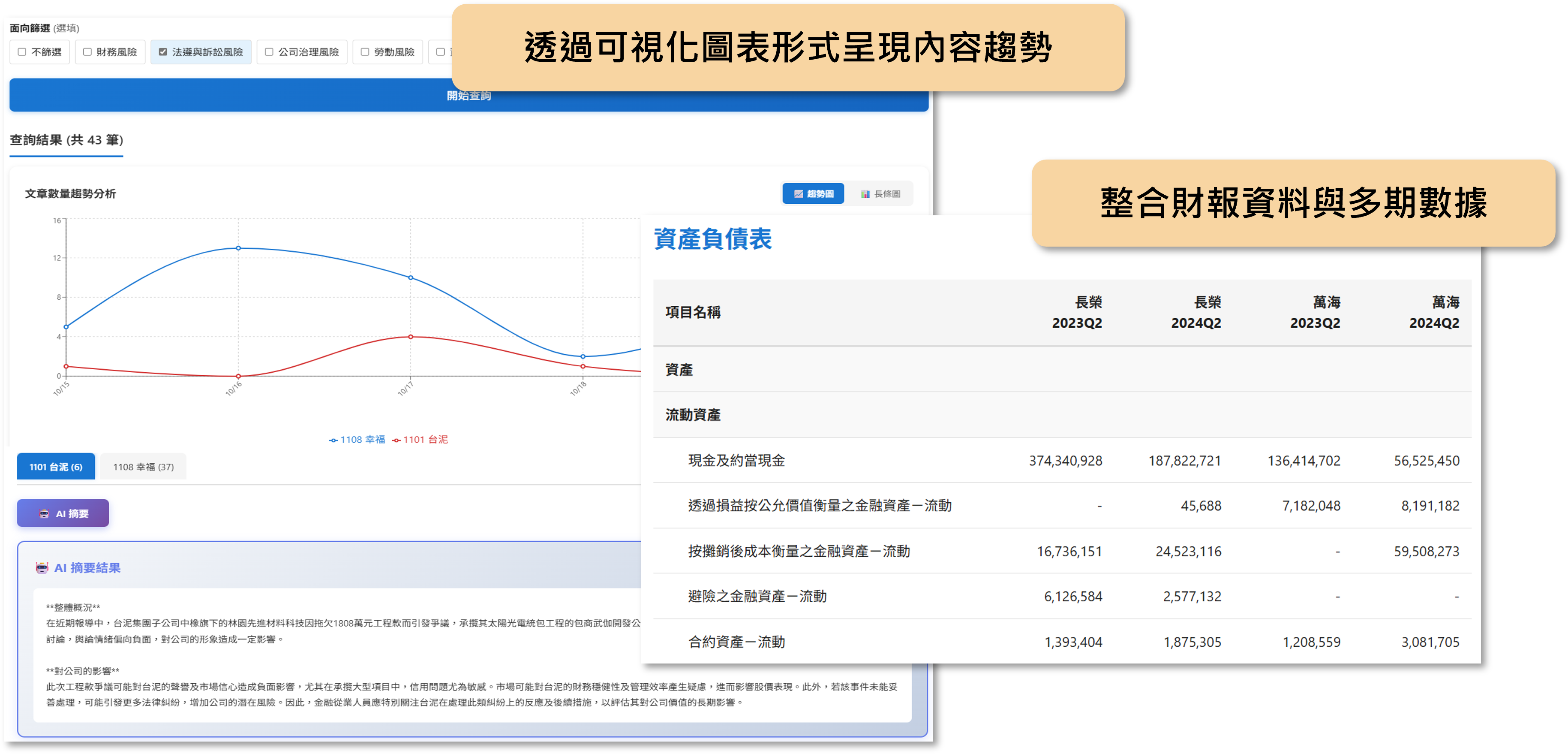
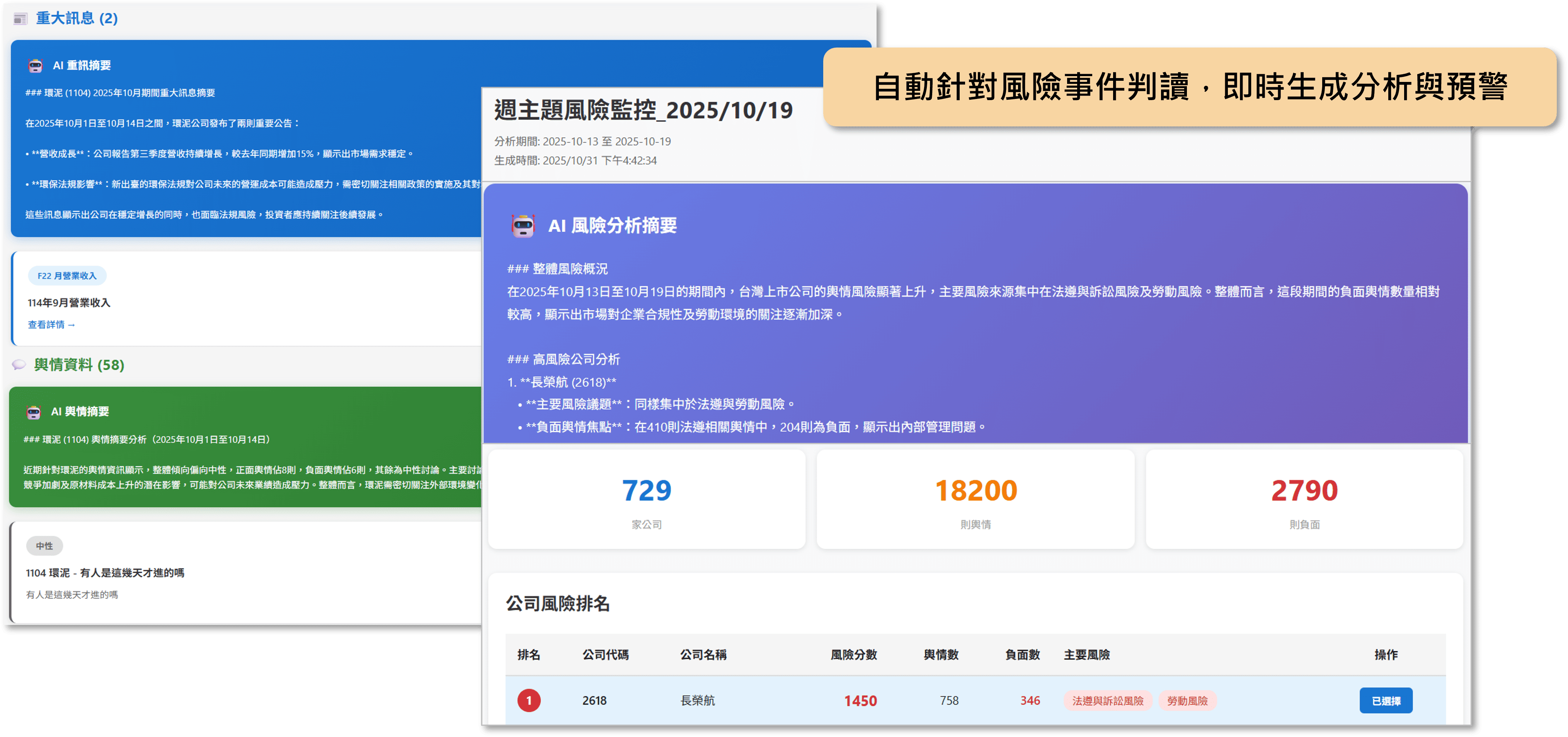
資料蒐集與彙整
從公司端收集公開說明書、年報、公告、契約書、會議紀錄等多來源資料。

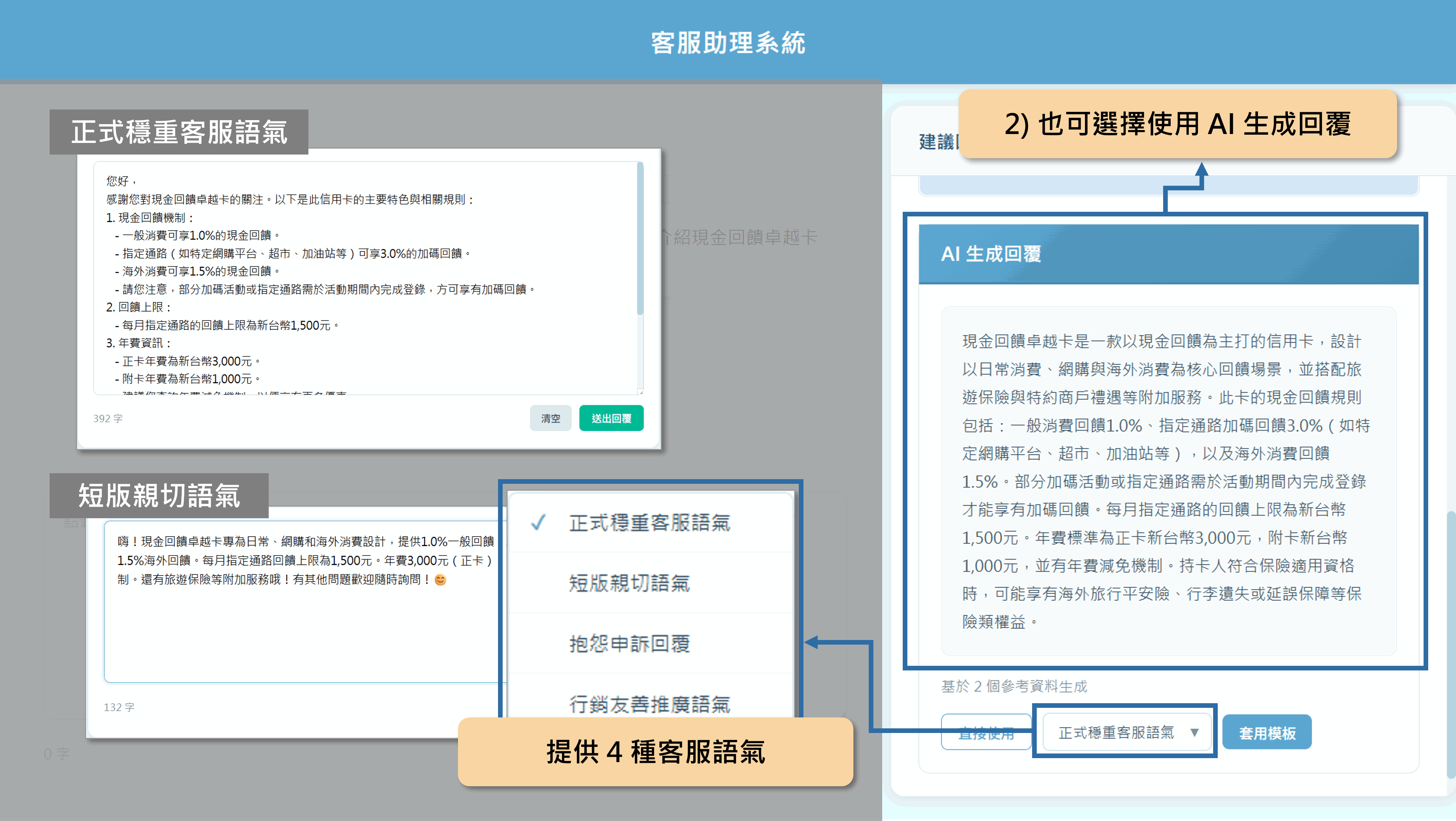
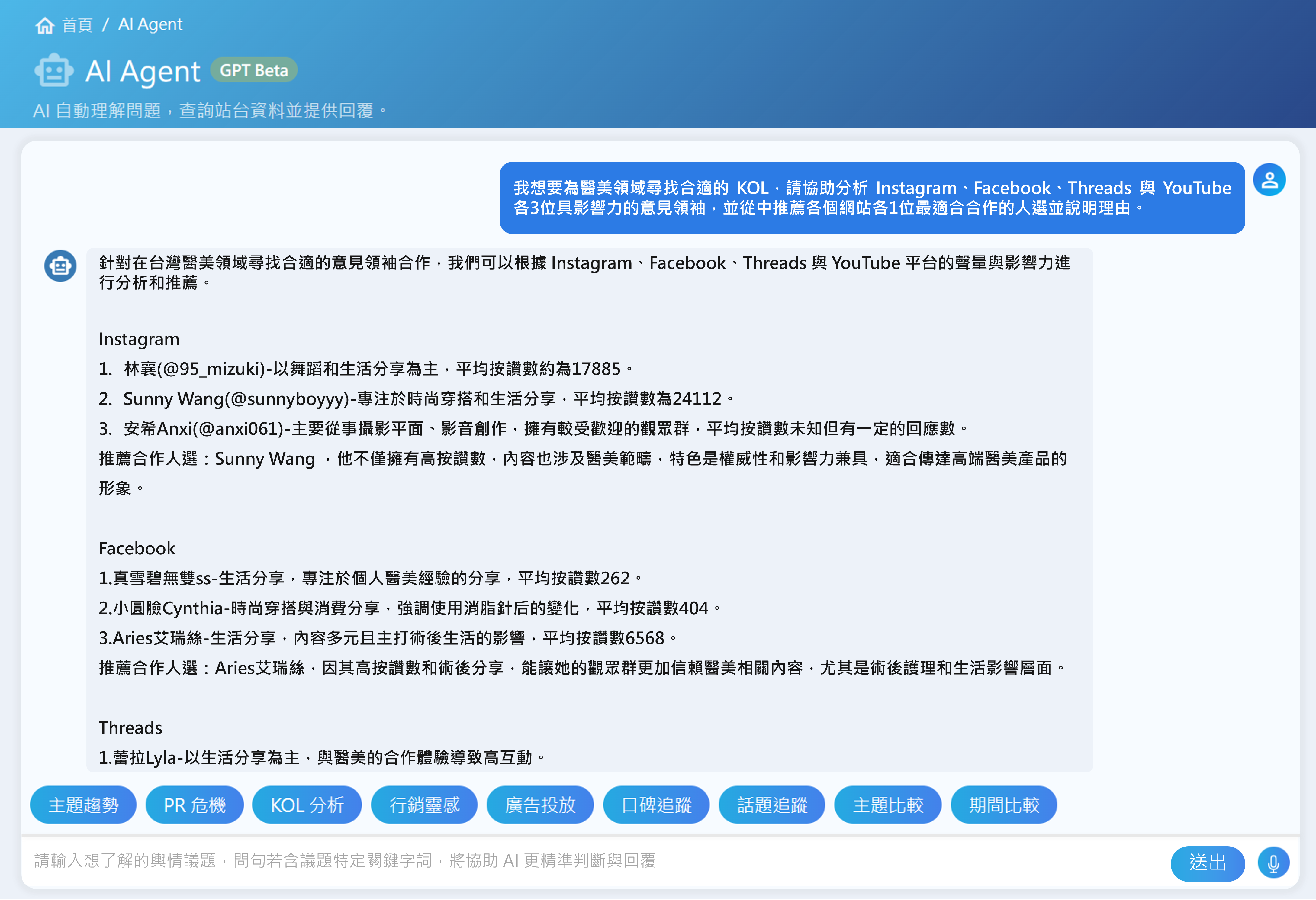
問答設定可根據不同情境,選擇模型與回應模式
用戶能根據不同使用情境,自行選擇適合的大語言模型(如 eLAND GOAT、GPT 系列、Gemini 及 Claude 等)與回覆模式。

搜尋內外部資料源,並可靈活優化查詢結果
可彈性選擇參考資料的來源,包括參考內部的特定文件或外部特定來源的輿情,並採用混合式搜尋,能夠動態調整全文檢索與向量搜尋的排序比重,確保最終結果貼近用戶的詢問意圖。

可自訂提示詞,生成符合特定架構的報告
用戶可透過設定提示詞,指定大語言模型生成特定語調、格式或範本之報告,系統亦會詳列參考資料來源,確保內容具備高可信度。

AI 大題
感情話題向來是社群上長期受到關注的焦點,從渴望脫單到交往後的磨合爭執,每個感情階段都有不同的核心課題。隨著大眾對親密關係所抱持的價值觀與立場日益多元,相關討論亦在社群中持續擴散與累積。透過 AI 輿情分析,我們從數據中歸納大眾關注的焦點,帶您了解當代親密關係中的行為動向與情感趨勢。

3/25 (三) 意藍 AI 研討會 熱烈報名中!
揭秘 AI Search 實戰架構,深度整合領域知識庫與智能搜尋技術,
並賦予企業串接多元生態的強大動能,助力企業解鎖數據潛能力。
立即前往報名!