如何破解電信詐欺隱藏線索?
AI 關聯分析技術在複雜案件偵查中的應用
本期 AI 知識庫亮點

偵查單位現行作業流程面臨的挑戰
- 資料量龐大且複雜性高:偵查單位每天要處理的資料來源多元,包括民眾舉報、金融交易資料、新聞報導、社群訊息等。由於資料的格式各不相同,內容範疇又橫跨廣泛領域,使得前期研判工作負擔大幅增加。
- 案件脈絡難以快速掌握:當詐騙集團以組織化方式運作,各成員僅負責詐騙流程中的其中一個環節,這類分工模式便會導致案件線索散落於不同文件中。因此,調查人員在偵查辦案時,需花費大量時間比對、整理與交叉驗證,才能看出人物間的關聯、資金流向或上下游共犯結構,並進一步拼湊出案件全貌。
導入生成式 AI 解決方案為偵查單位帶來哪些效益
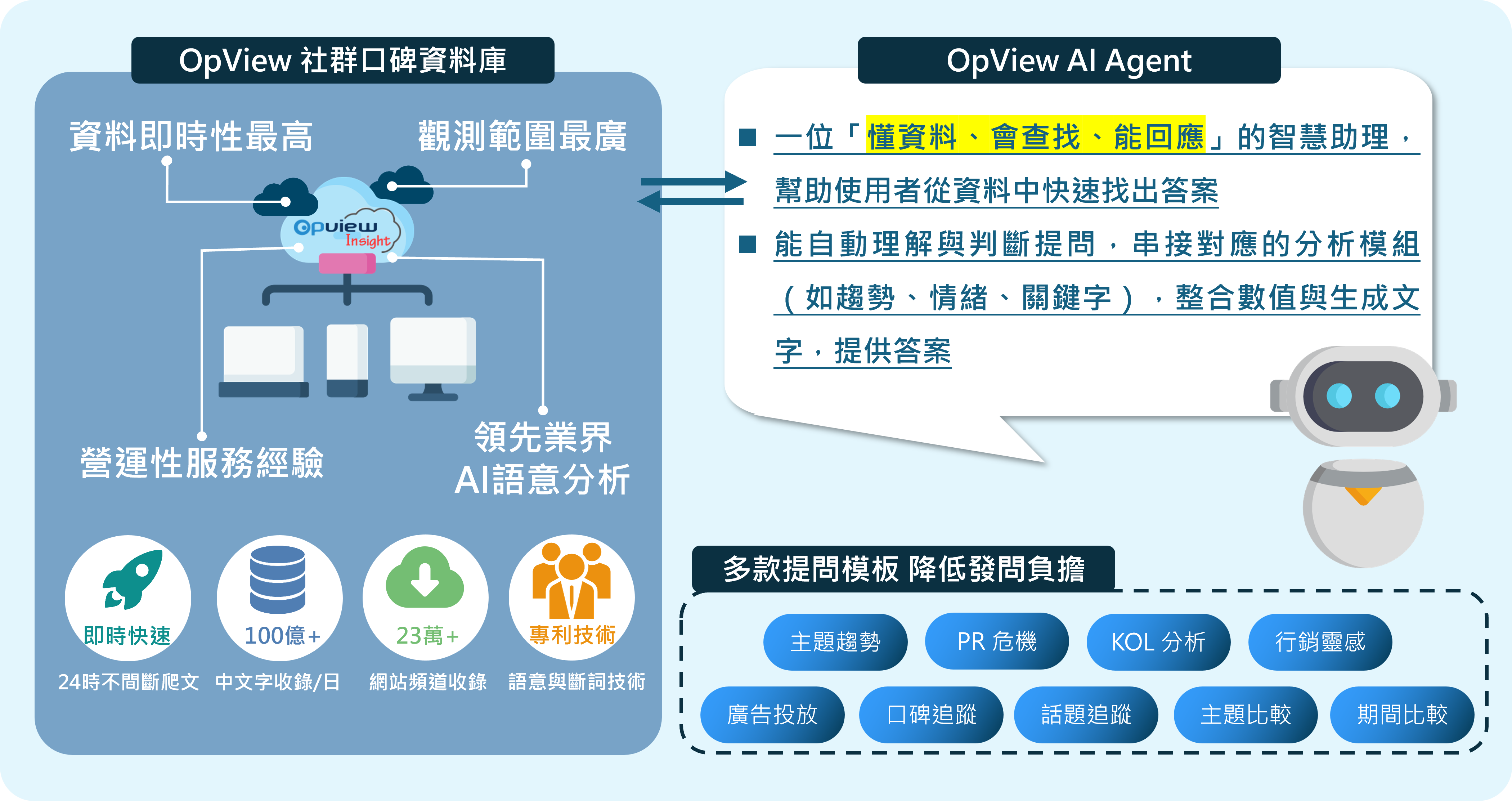
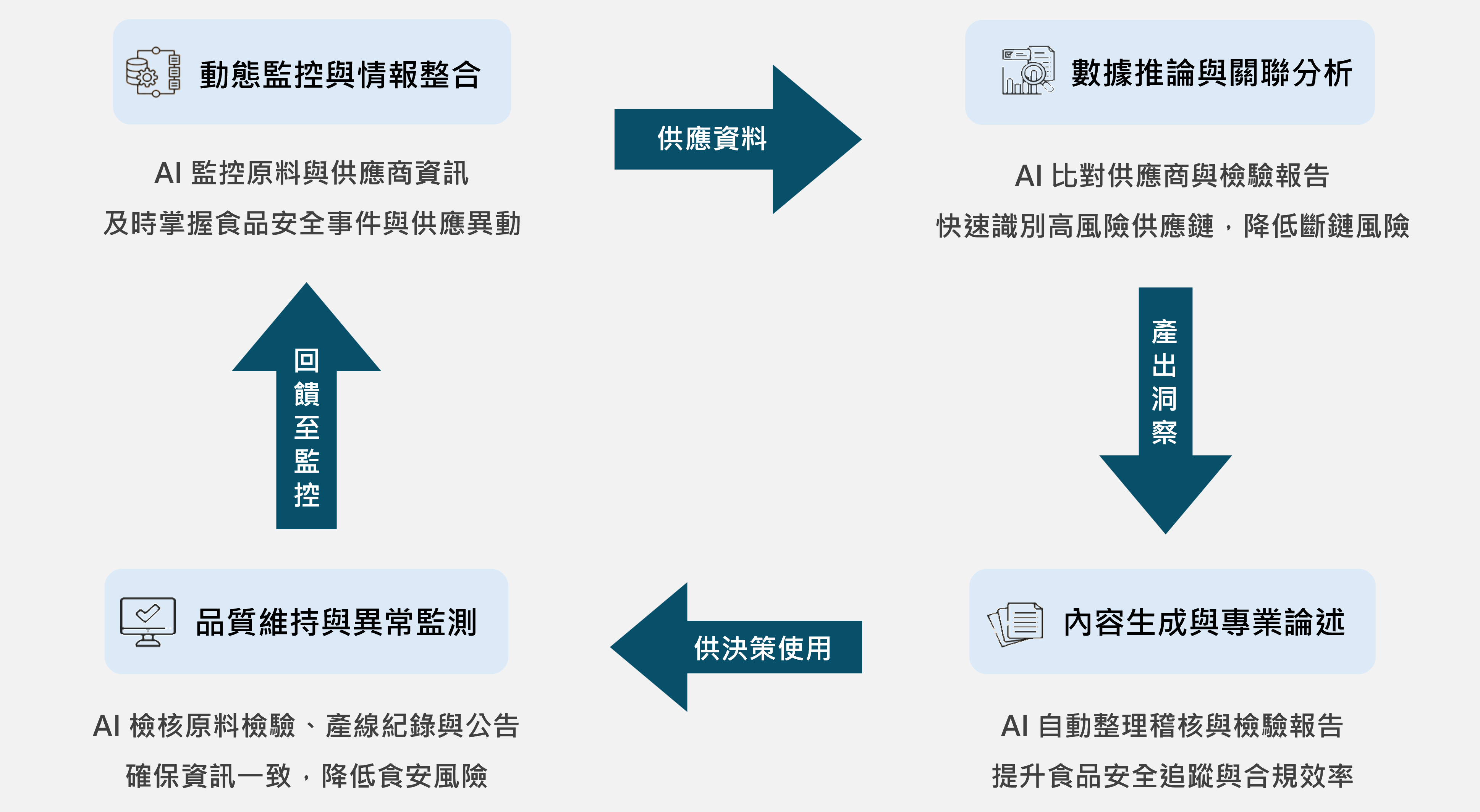
為解決上述痛點,意藍資訊協助偵查單位建置並導入「電信詐欺防制 AI 分析平臺」。本系統以檢索增強生成(RAG)架構為核心,整合生成式 AI、自然語言處理(NLP)、大型語言模型(LLM)及關聯分析等技術,並具備 Agent 多步驟執行任務的能力,在接受到指令後能自動跨來源檢索、比對並統整資料,重塑從資料彙整到案件研析的流程。整體系統可分為三大核心模組:自動摘要、關聯分析以及圖表生成,協助調查人員更快掌握案件全貌。
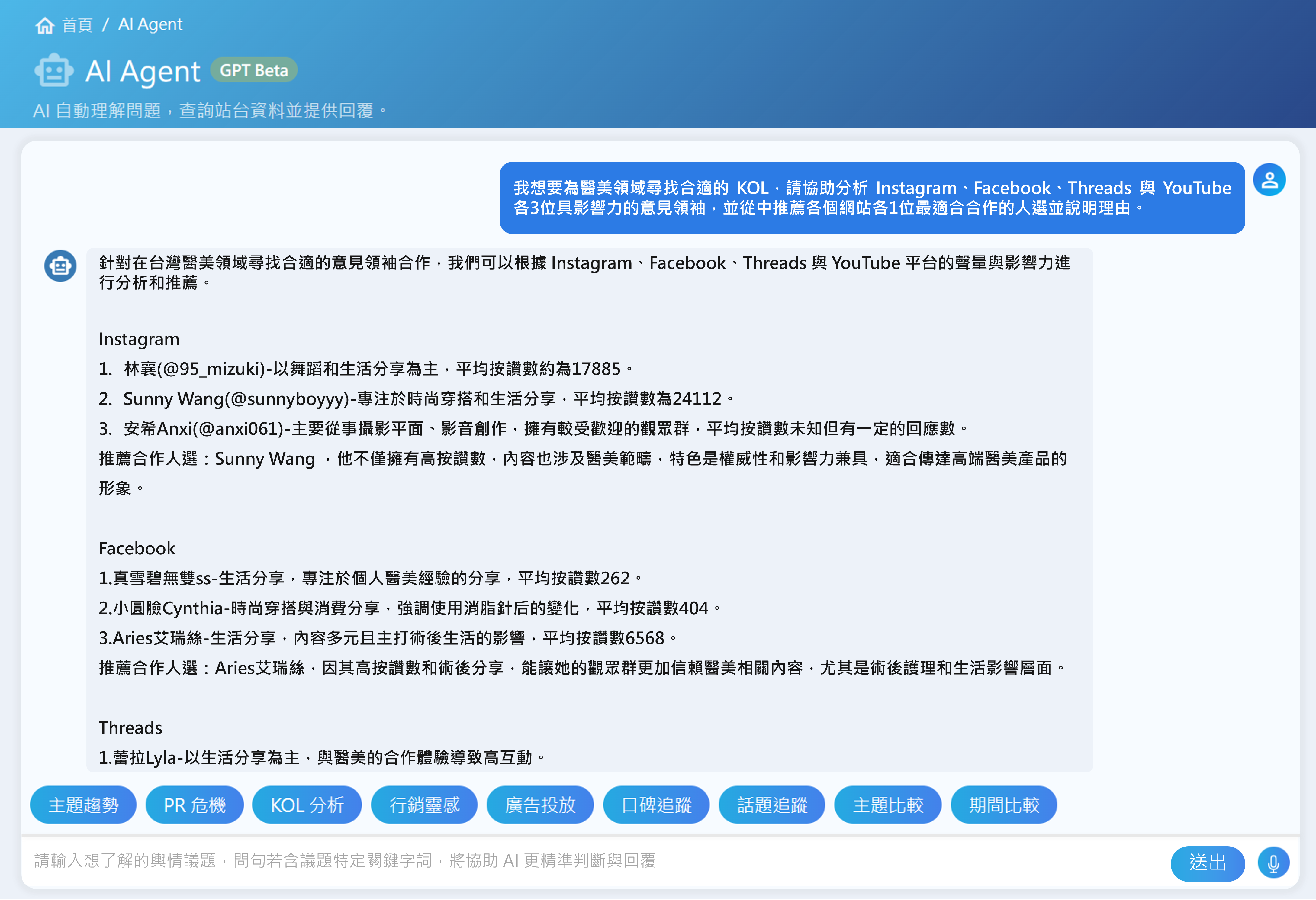
- AI自動彙整與摘要可信結果:在偵辦電信詐欺案件時,調查人員常需要在短時間內了解人物、帳戶、交易紀錄與通訊內容等核心資訊。在檢索增強生成(RAG)架構與跨來源檢索能力的基礎下,調查人員提供人物姓名、公司或行號等與案件相關的線索資訊後,系統便會自動整合多來源資料與文件內容,進行語意分析與重點萃取,進而生成包含商工登記資料、戶籍資料、裁判書等資訊的摘要結果,並於回覆中提供資料的參考來源,有效縮短跨單位比對與人工查核所需時間。
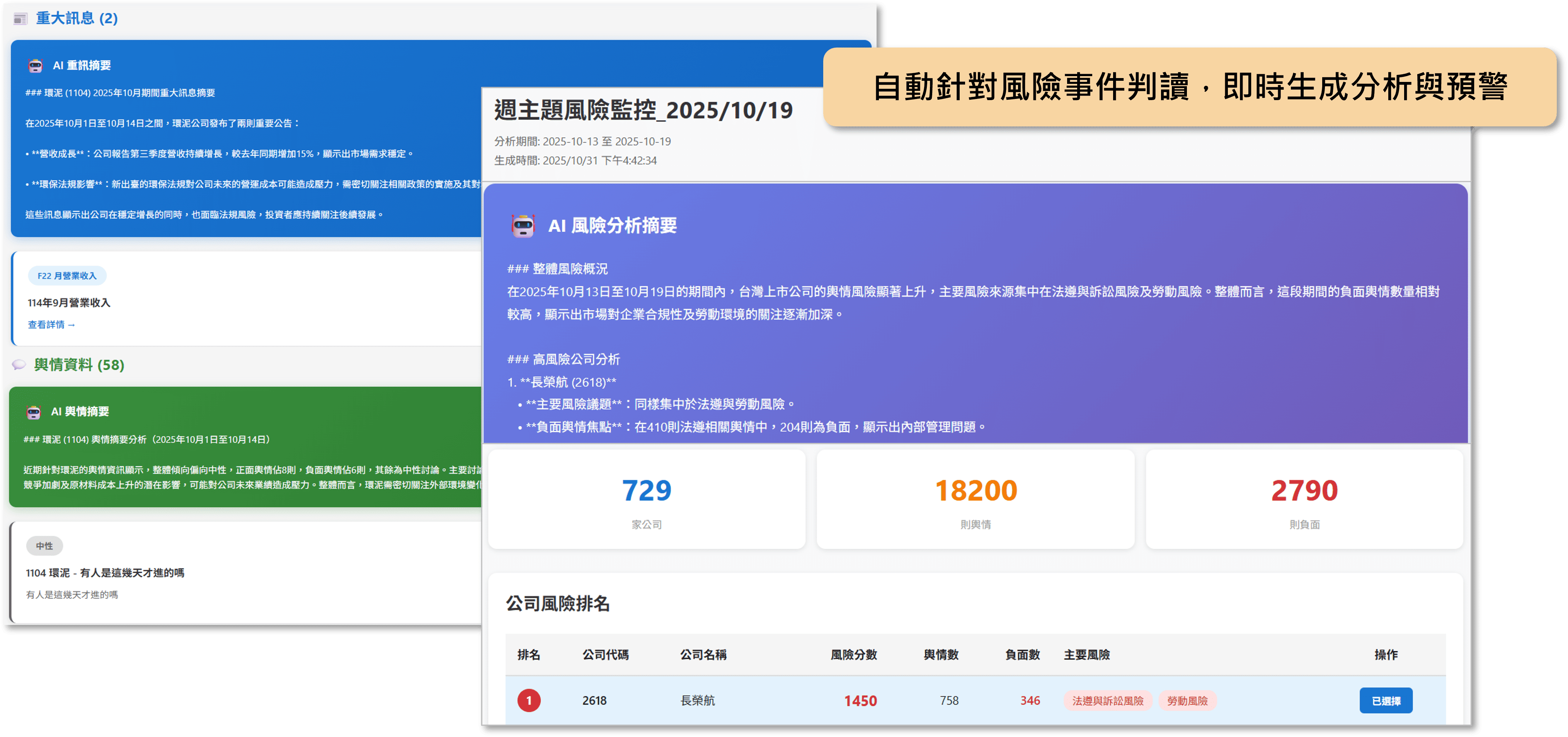
- 關聯分析模組:利用 NLP(自然語言處理)和 LLM(大型語言模型)在多筆資料中找出人物、公司、地點、電話、帳戶等資料之間的關聯性,分析案件的交易關係或資金流向,並於生成的關聯結果中標示對應的文件與段落。如此一來,調查人員不僅能清楚掌握案件全貌與發展脈絡,也能夠依案件需求回溯原始內容,有助於未來查證、複審與移送書撰寫等作業流程。
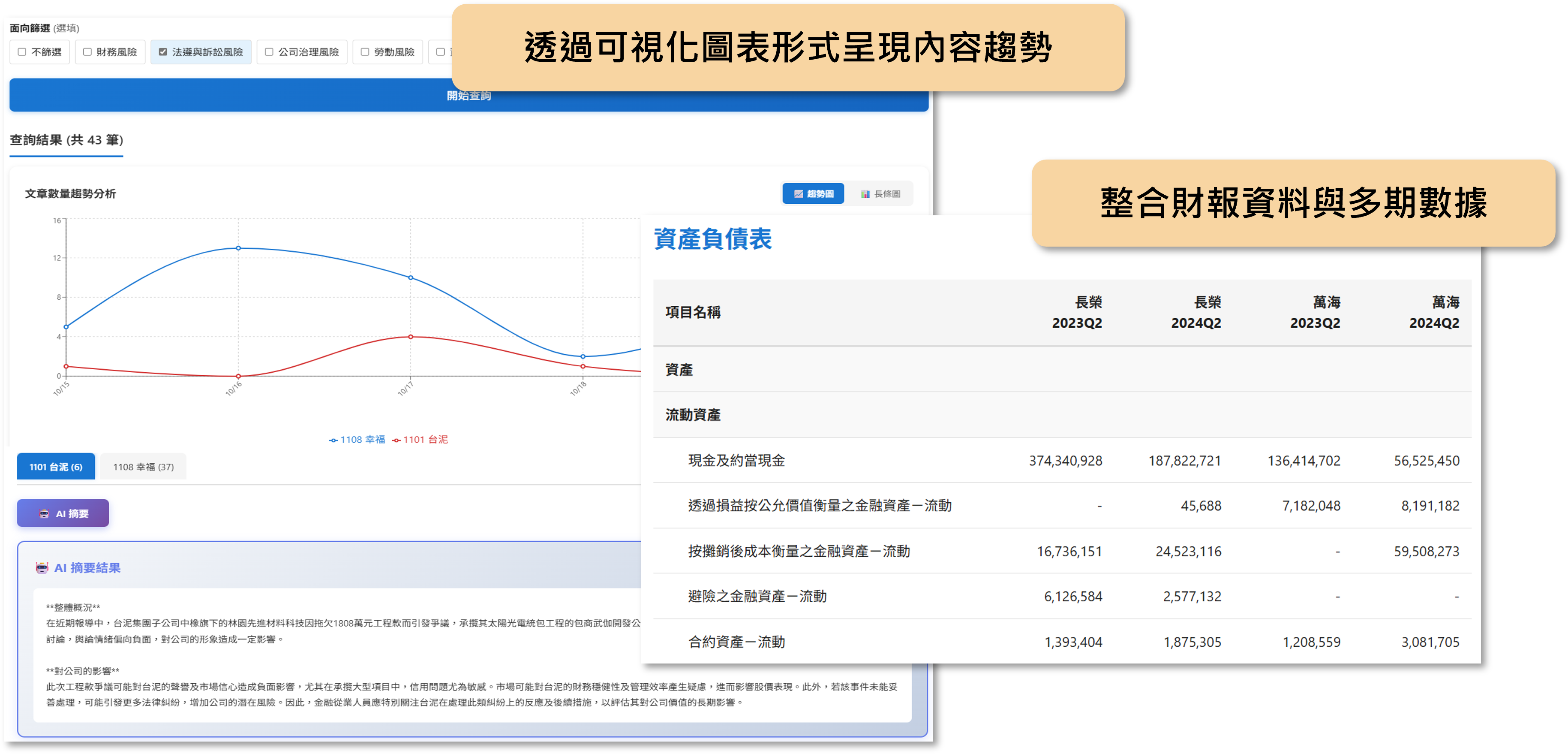
- 圖表生成模組:藉由前兩個模組找出核心資訊與關聯性後,系統會將人物關係、資金流向等分析結果轉成視覺化圖表,讓案件脈絡一目了然。透過導入此模組,當調查人員面對人物關係與金流複雜的案件時,不僅能避免人工判讀造成的錯誤,若案件規模擴大,也能以現有架構研判新增之資料,節省時間成本。
透過導入「電信詐欺防制 AI 分析平臺」,偵查單位得以用更系統化的方式整合多來源資料,快速掌握關鍵線索與案件脈絡,使原先需大量依賴人工比對的研析工作,能在更短時間內完成,進而提升研析效率與判斷精準度。
常見問題 FAQ
Q1:為什麼現在偵辦電信詐欺案件,光靠人工比對已經不夠了?
A:主因是詐騙集團走向「組織化分工」與「科技化犯罪」,導致線索極度破碎。
現在的詐騙流程(如假投資、假社群)由不同成員分工,關鍵的人物、帳戶、電話與金流資訊散落在各種不同格式的文件與資料庫中。若僅靠人工比對,調查人員會耗費絕大部分時間在整理資料,難以在第一時間拼湊出完整的共犯結構與資金流向。
Q2:AI 如何協助調查人員從大量的「非結構化資料」中快速抓出重點?
A:透過 AI 自動摘要模組與 NLP 技術,系統能自動進行多來源資料的「語意分析」與「重點萃取」。
調查人員只需輸入姓名、公司或帳戶等關鍵字,AI 就能跨來源檢索商工登記、戶籍、裁判書等資料,並自動生成包含核心線索的摘要報告。這不僅縮短了跨單位查核的時間,更能確保關鍵資訊不被遺漏。
Q3:「電信詐欺防制 AI 分析平臺」如何找出隱藏的人物與金流關聯?
A:利用關聯分析模組(NLP+LLM),系統能自動識別多筆資料間的隱性聯繫。
即使線索散落在不同文件,AI 也能辨識出人物、電話、帳戶與地點之間的邏輯關聯,並自動分析資金的流向或上下游關係。最重要的是,系統會在結果中標示對應的文件段落,讓調查人員可以隨時回溯原始內容進行查證。
Q4:面對複雜的人物關係與資金往來,AI 如何讓案情變得「一目了然」?
A:系統內建「圖表生成模組」,能將分析結果自動轉化為視覺化圖表。
當案件涉及的人數與轉帳次數規模龐大時,人工判讀極易出錯。AI 能根據關聯分析模組的結果,自動繪製出人物關係圖與資金脈絡圖。即使後續案件規模擴大,也能快速加入新資料進行研判,大幅節省人工繪圖與更新的時間成本。
Q5:AI 生成的偵查摘要內容,在法律與審核上具備可靠性嗎?
A:具備。系統基於 RAG 架構,所有回覆內容均提供「資料參考來源」。
與一般的生成式 AI 不同,此系統在提供摘要或分析時,會明確標註是引用自哪份文件或哪段紀錄。這種「有所本」的機制方便調查人員進行複審、驗證,並直接用於移送書的撰寫,確保偵查結果的嚴謹性。
Q6:導入 AI 分析平臺後,對於偵查單位的整體效益為何?
A:核心效益在於「系統化整合」與「大幅提升研析效率」。
透過 AI 輔助,偵查單位能以更系統化的方式整合民眾舉報、金融紀錄與通訊內容等分散情資。這不僅讓原本需耗時數週的關聯研析在短時間內完成,更提升了判斷的精準度,強化了打擊組織化犯罪的偵查戰力。