
如何利用 AI 掌握即時災情?
看災防中心如何透過 AI Search for KM 落實循證決策
近年來, AI 技術的持續創新突破,推動了政府和企業內的數位變革,如何導入並善用AI以提升服務的效率和品質,成為各單位組織的重要課題。
國家災害防救科技中心(National Science & Technology Center for Disaster Reduction,以下簡稱災防中心或NCDR)為政府於2003年設立的專業機構,多年來專注於災害風險管理和防救科技的研究;為了能在災害發生時更即時地掌握災情、強化危機事件處理能力,災防中心與意藍資訊合作,導入意藍「AI Search For KM」系統,運用生成式AI與自然語言模型建構「災害防救知識問答平台」,大幅提升災情資訊處理效率,並以數據支持決策判斷,為智慧城市發展奠定穩固基礎。
本期 AI 知識庫亮點

災防中心背景與需求介紹
國家災害防救科技中心成立於2003年,主要任務在於提升台灣在面對各種自然災害時的應變能力與減災效果、確保民眾生命財產安全。面對台灣頻繁發生的地震、颱風、土石流等天然災害,災防中心不僅需在災前做好準備,也必須在災害發生後迅速掌握最新狀況,整合、分析各類災情資訊以協助政府及相關單位作出精確的應對決策,並提供必要的預警或通報。
隨著大量災情資訊不斷累積,災防中心在知識管理升級方面的需求日益增強;另一方面,數位化時代下社群媒體和網路社群亦成為災情資訊快速傳播的主要來源,這些公開管道中的資訊量龐大且更新頻繁,如何高效蒐集、結構化、分析並運用這些來自各地的災情回饋,也是災防中心需面對的重要課題之一。
以AI Search for KM 建構「災害防救知識問答平台」
- 資料蒐整與預處理:蒐集歷年來既有的災害事件情資研判報告、即時觀測數據(如雨量、河川水位等),以及各大公開媒體、Facebook粉絲團、Dcard、巴哈姆特、Mobile01及Ptt等公開討論區的地區版等資料,經過清整、結構化與預處理,將結構化與非結構化資料均轉換為模型可理解的格式。
- 語意分析與標記:透過語意分析技術,讓AI自動判別每一篇災情文章內容中提及的地理資訊、災害事件以及災情程度等,將這些重要詞彙辨識出來並自動標記,以利後續的索引和檢索。
- 大語言模型選擇:評估各個大語言模型在災害防救領域問答的真實性、回覆速度、正確性、可讀性、理解上下文與統整能力等效果,選擇最適用的自然語言模型。
- 建立資料向量索引、設定參數:提高檢索與問答時的效率及準確性,確保AI模型對災害知識有精準的搜尋能力與答覆效果。
透過AI Search for KM 所提供的知識平台,災防中心便能夠針對歷年災害事件、抑或即時災情進行問答,系統會逐步拆解使用者所輸入的問題,再透過大語言模型(Large Language Model, LLM)及檢索增強生成技術(Retrieval-Augmented Generation, RAG)生成完整回覆。
以颱風相關的問題為例,使用者可對系統以口語文字方式提問,如「哪個地方災情最嚴重」、「哪些鄉鎮的河川水位超過一級警戒」等等,AI Search for KM便會即時調用內部知識庫及外部即時數據,找出與使用者提問最相關的多個參考內容,從中綜合歸納出答覆。AI Search for KM具備簡便、容易使用的介面,能快速統整內部及外部、文字及數值的各類數據,在分秒必爭的防災與救災時刻,提升作業效率。

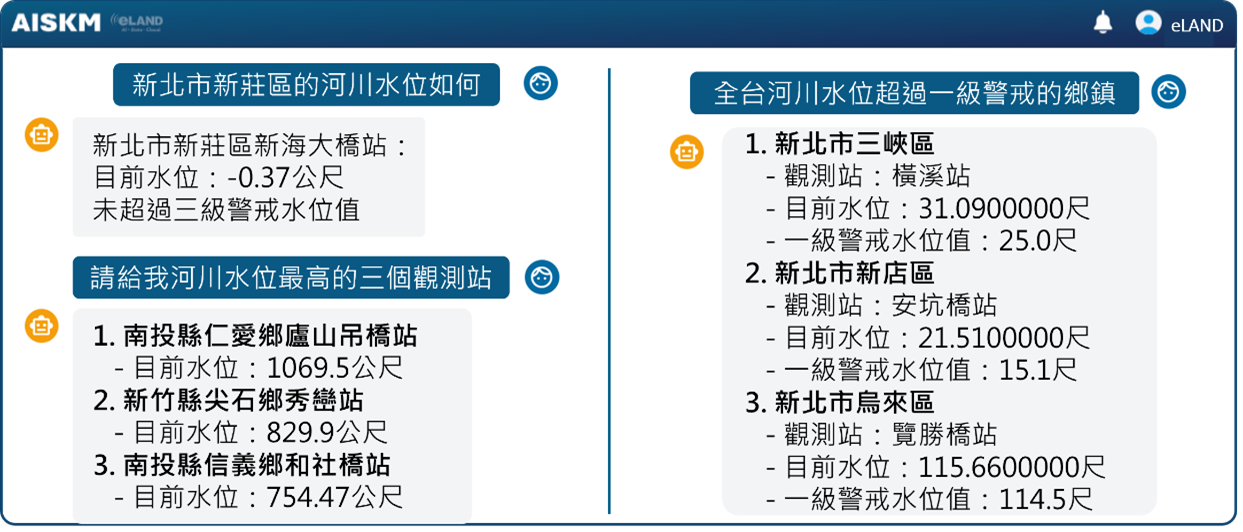
▲ 問答情境2 – 調用即時數據,掌握全面性災情
透過與意藍合作導入AI Search for KM系統,災防中心能夠更高效地整合歷史與即時災害數據,在災害發生前後做出精確的災情管理判斷,及時釐清災情狀況並調度人力與資源,落實循證決策、全面提升災害應變能力;未來意藍也將持續與災防中心攜手,逐步實踐智慧城市願景。
常見問題 FAQ
Q1:災害防救科技中心為何需要導入 AI 知識管理系統?
A:為了在分秒必爭的災害發生時,能快速整合、結構化並分析海量的分散情資。
災防中心面對頻繁的地震、颱風等災害,需處理包括歷年情資報告、即時觀測數據,以及來自社群媒體(FB, PTT, Dcard 等)的龐大非結構化資訊。導入 AI Search for KM 能自動清整並標記這些資料,大幅提升災情處理效率,支撐政府作出精確的應對決策。
Q2:AI Search for KM 如何協助災防單位蒐集散落在網路上的民眾災情回饋?
A:系統透過 ETL 數據處理技術,能自動爬取並結構化各大社群媒體與討論區的資訊。
面對 PTT 地區版、Dcard 或媒體新聞中破碎的災情訊息,系統會先進行清整與預處理,將文字轉換為模型可理解的格式。這解決了社群資訊量龐大且更新頻繁,人工難以即時過濾與彙整的難題。
Q3:當災害發生,AI 如何透過一篇社群文章自動判斷嚴重程度?
A:透過深度語意分析技術,AI 能自動辨識並標記文章中的地理資訊、事件類型與災情程度。
系統能自動識別文章中提及的「路段」、「水位」或「倒塌情況」,並進行關鍵標記。這有助於後續的索引與檢索,讓災防單位能第一時間篩選出最緊急的求援或損害回報,減少資訊遺漏。
Q4:災防中心的問答平台如何確保 AI 產出的回覆是真實且準確的?
A:結合了檢索增強生成(RAG)技術,要求 AI 必須根據內部知識庫與即時數據來回答。
系統不只依賴模型既有的知識,而是會調用災防中心專屬的歷史數據庫與即時觀測數據。當使用者提問時,AI 會找出多個參考段落進行綜合歸納,並註明出處,確保生成的內容具備高度的可驗證性,避免「AI 幻想」。
Q5:人員可以用多口語的方式對系統提問?系統聽得懂複雜的災情問題嗎?
A:使用者可以用非常直覺、口語化的自然語言進行提問。
例如直接詢問「哪個地方災情最嚴重?」或「哪些鄉鎮河川水位超過一級警戒?」。AI Search for KM 會逐步拆解問題中的核心關鍵字,自動串接雨量或水位等數值數據,並將複雜的數據轉化為白話的總結回覆,大幅降低系統操作難度。
Q6:面對多樣化的災害任務,如何選擇最適合的大語言模型 (LLM)?
A:意藍會針對模型的真實性、回覆速度與上下文統整能力進行全面評估。
在建構「災害防救知識問答平台」時,會針對災害防救領域的特殊語境,測試不同模型(如 OpenAI, Llama 或在地模型)的正確性與理解力,最終選擇能平衡「效能」與「成本」的最優模型,確保在救災關鍵時刻不卡頓。
Q7:導入 AI Search for KM 後,對於政府的「循證決策」有什麼具體貢獻?
A:系統能實現歷史經驗與即時數據的整合,提供科學化的判斷依據。
災防中心能快速比對歷年災害事件的應對經驗,並對比當下即時災情,協助決策者在釐清狀況後,精確地調度人力與資源。這不僅提升了災害應變能力,也落實了數據驅動的智慧城市治理願景。