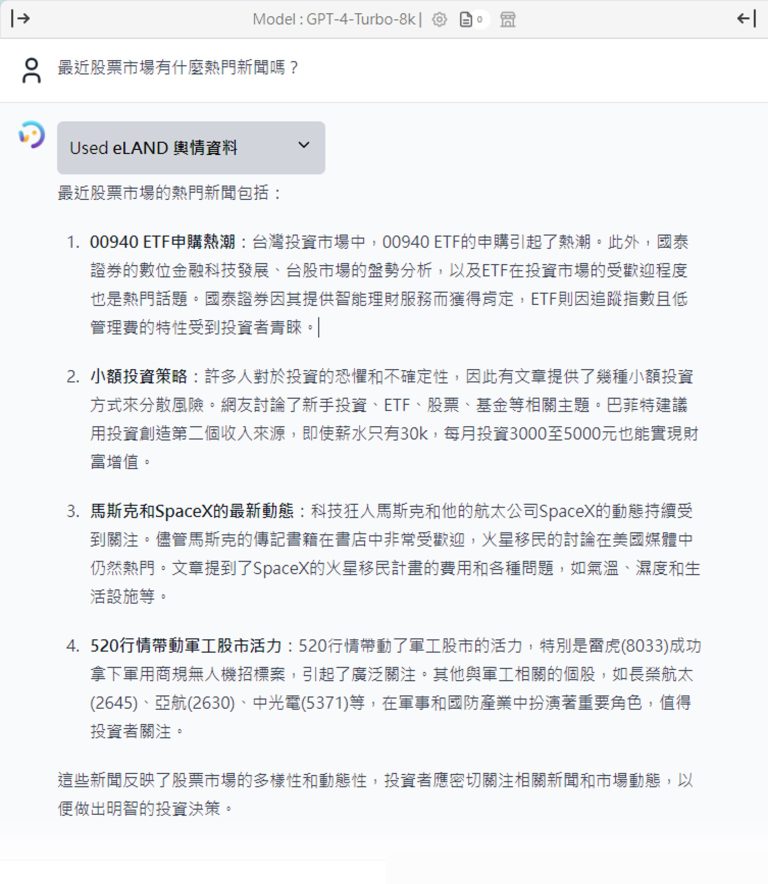
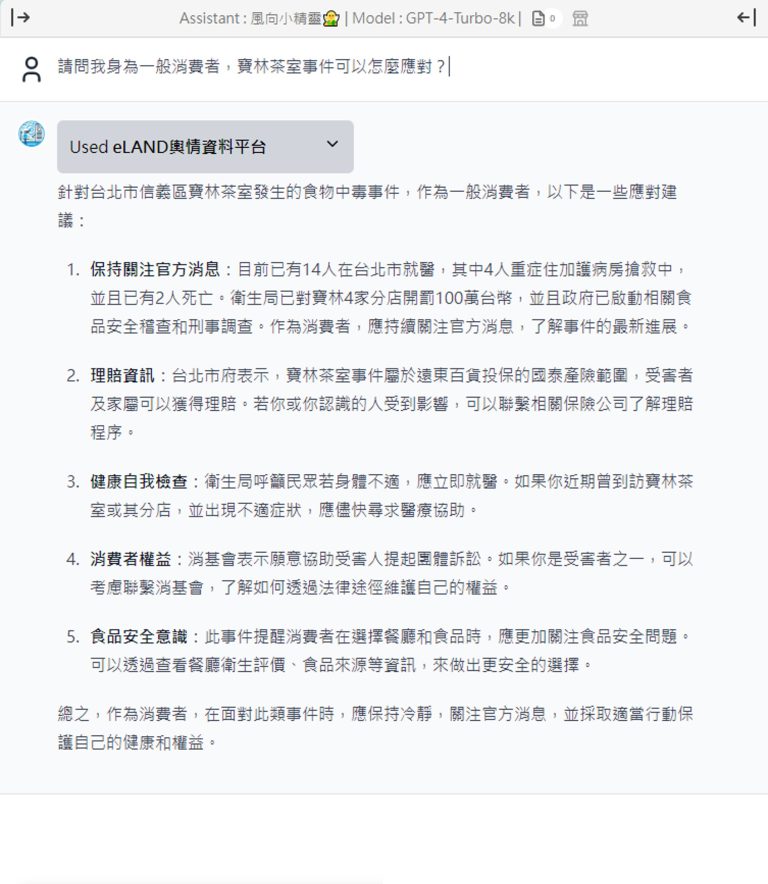
新一代生成式AI知識管理系統 AI Search for KM介紹說明(影片)
意藍新一代生成式AI知識管理系統AI Search for KM,結合了生成式AI、搜尋引擎和NLP技術,為企業組織提供了全新的知識管理解決方案,更加地容易上手使用。本次我們便以影片形式來為大家介紹,AI Search for KM如何協助各企業或機關單位快速檢索和應用組織內部的重要知識,解決傳統知識管理中的痛點,提升工作效率和資料安全性。

影片精華
企業知識管理常見痛點是什麼?
知識管理對於企業來說至關重要,可以協助企業內部的專業知識得以保存、傳承、優化,維持企業競爭優勢。然而現今普遍的企業知識管理系統仍存在幾個常見的痛點:
學習企業知識庫並進一步內化所產生的人力成本過高
知識的運用不夠自動化、搜尋不夠智能化
系統不好上手
無法區分部門/層級權限
>>詳細痛點剖析,請見AI Search for KM 基本介紹0:23
AI Search for KM 服務特色有哪些?
AI Search for KM 是一款新一代的生成式AI知識管理系統,具有以下五大核心特色:
支援多種格式
包括PDF、Microsoft Office等多種職場常見的檔案格式,滿足各組織單位需求
權限控管機制
可針對不同部門和機敏資料進行權限管控,確保資料安全性
支援全文檢索
支援全文檢索功能,讓使用者能夠輕鬆快速地找到所需資訊
支援口語問答
支援口語化的對話問答功能,提升使用者操作便捷性
可選擇地端/雲端運算方案
可根據單位需求選擇部署在地端或雲端,兼顧安全性與效能
>>詳細服務特色說明,請見AI Search for KM 基本介紹2:22
AI Search for KM 應用情境有哪些?
AI Search for KM 在產業中的應用情境廣泛。例如,在知識檢索方面,AI Search for KM能夠精準引用企業知識庫中的資料,提供使用者準確的答案和資料來源,從而提高搜尋效率和可信度。此外,在對話問答方面,AI Search for KM能夠以口語化的方式回答使用者提問,降低使用者的學習成本,提升使用者體驗。
>>詳細 是非問答/名詞解釋/情境問答 應用情境,請見AI Search for KM 基本介紹5:20
AI Search for KM vs 一般生成式AI 有什麼差異?
有別於一般的生成式AI,AI Search for KM有著更多的優勢。首先,在資料準確性與可信度方面,AI Search for KM能夠根據企業建構的知識庫提供準確的答案和資料來源,避免因不實際資料而產生的錯誤或幻覺。再與一般常見的生成式AI如GPT-4相比,透過提供組織專屬的資料給AI Search for KM ,系統便可以根據專業領域知識來精準回覆,不限於網路公開資料。
>>詳細說明AI Search for KM與一般生成式AI差異,請見AI Search for KM 基本介紹7:29
AI Search for KM 的服務導入方式?
想導入AI Search for KM服務,首先需要評估並整理組織內部的資料庫與知識文件,確定哪些內容是重要且需要被整合進系統的,下一步即可根據組織的需求選擇 Web Service API,或是線上可登入的服務平台等方式來導入服務,並進行生成式 AI 等參數設定,之後使用者便可以直接開始使用 AI Search for KM 來進行知識管理!